Bayesian optimization (BO) is a widely used approach for computationally expensive black-box optimization such as simulator calibration and hyperparameter optimization of deep learning methods. In BO, a dynamically updated computationally cheap surrogate model is employed to learn the input-output relationship of the black-box function; this surrogate model is used to explore and exploit the promising regions of the input space. Multipoint BO methods adopt a single manager/multiple workers strategy to achieve high-quality solutions in shorter time. However, the computational overhead in multipoint generation schemes is a major bottleneck in designing BO methods that can scale to thousands of workers. We present an asynchronous-distributed BO (ADBO) method wherein each worker runs a search and asynchronously communicates the input-output values of black-box evaluations from all other workers without the manager. We scale our method up to 4,096 workers and demonstrate improvement in the quality of the solution and faster convergence. We demonstrate the effectiveness of our approach for tuning the hyperparameters of neural networks from the Exascale computing project CANDLE benchmarks.
Usually, the centralized architecture is used in parallel Bayesian optimization. In this architecture, a single master process suggests new configurations to be evaluated by multiple workers. When scaling, this architecture can create congestion issues at the level of the master when many workers become idle and request new configurations. The duration taken by the master to re-sample new configuration therefore becomes critical.
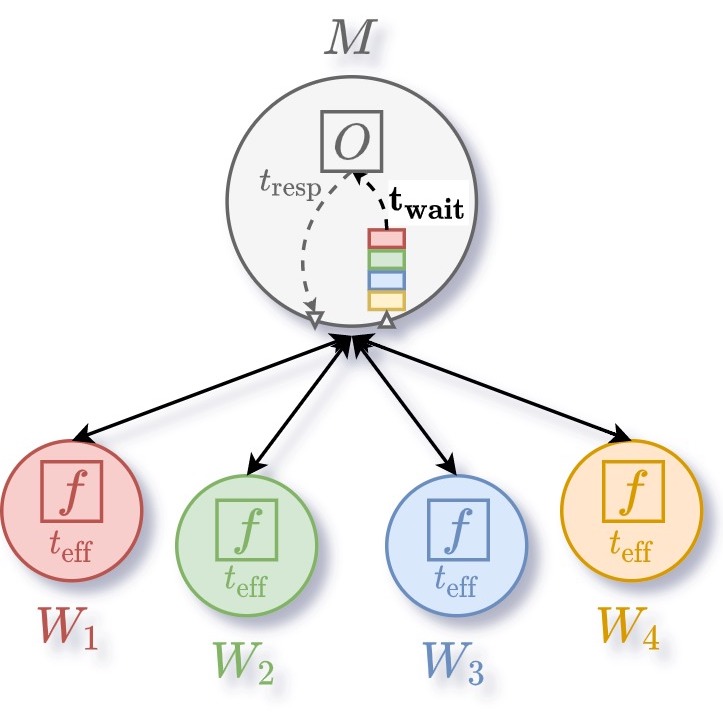
In the distributed architecture, each worker has its own optimizer and does not need to wait for other workers to be processed in a single queue. The request of workers is directly taken into consideration by the master. Also, the communication between each optimizers is performed asynchronously.
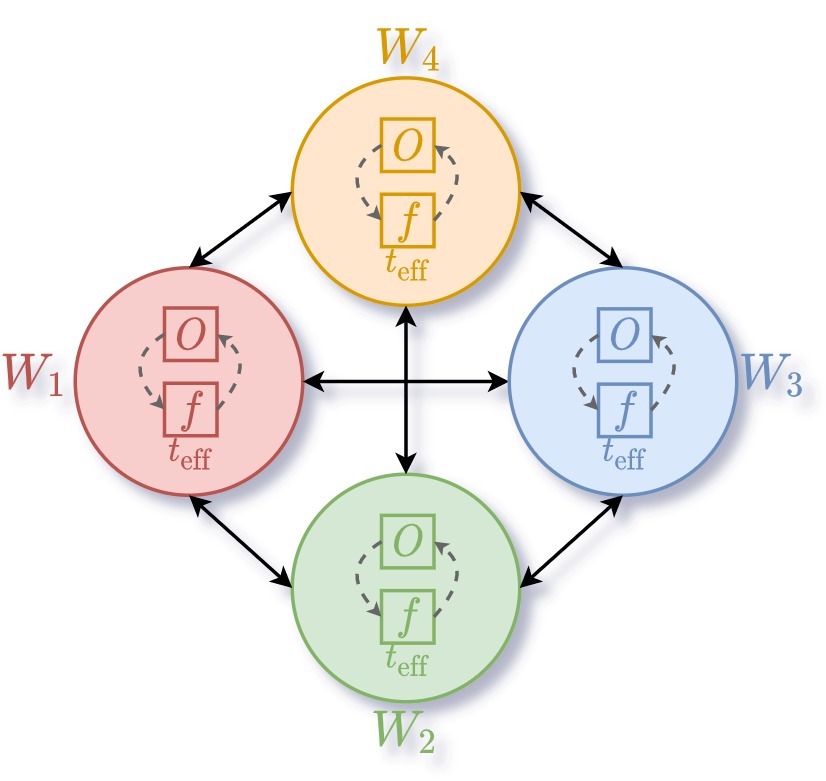
In our experiments, we start by evaluating our method (ADBO+qUCB) against the state-of-the hart distributed strategy (SDBO+bUCB) which is synchronous and using a stochastic acquisition function (to reduce the need for communication, performed only every 10 iterations). If we look at the evolution of the objective value (where the goal is to minimize the Ackley function), it is clear that our strategy converges faster and to better solution.
Then we see that the effective utilization (i.e., time spent in actual computation of the black-box function) is about 30% higher for our method than the compared baseline.
Finally, we evaluate our strategy on the task of hyper-parameter optimization of deep neural network. For this we use only 64 GPUs in parralel where each GPU is attributed to one worker. We compare our strategy (ADBO+qUCB) against asynchronous centralized random search (RD+ACBO), asynchronous Gaussian process-based Bayesian optimization (GP+ACBO) and asynchronous successive halving (ASHA). In this blog post we present shortly the result for the Combo dataset (from the Exascale Computing Project - Candle) where the goal is to predict the growth percentage of Cancer cells given a cell line molecular features and the descriptors of two drugs. In the comparison of objective plot we can see that our method find better solution faster, even better than a pruning strategy such as ASHA (goal is to maximize y-axis).
Then if we look at the effective utilization, it is clear that GP+ACBO is having difficulties to maintain a good level of utilization compared to other search algorithms.
In fact this is explained by the cubic complexity of model fitting in Gaussian process which we vizualise in the following plot.
To conclude, we presented an overview of our results for asynchronous distributed Bayesian optimization and demonstrated its advantages for scaling to large number of workers.